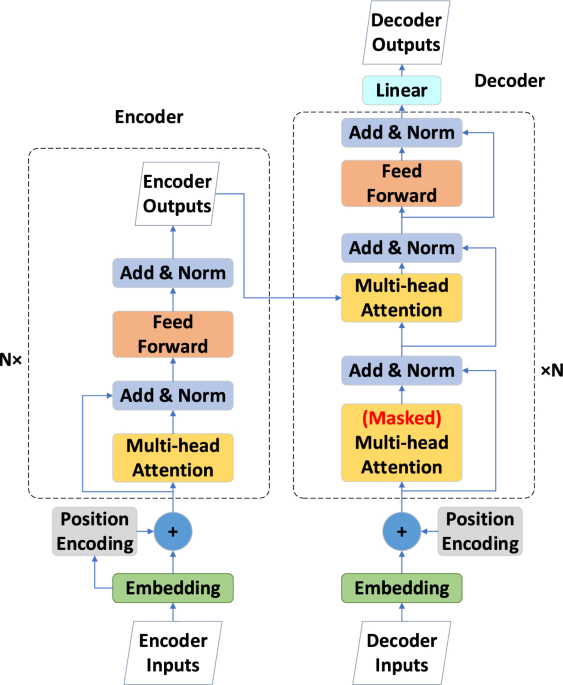
Architecture du modèle Transformateur
De nos jours, l’architecture encodeur-décodeur est largement utilisée dans les problèmes de traduction automatique, et le Transformer en est un exemple remarquable. L’encodeur code l’entrée \(X^{t} = \left\{ {x_{1}^{t} ,x_{2}^{t} , \ldots ,x_{{L_{x} }}^{t} } \right\}\) en un état caché \(H^{t} = \left\{ {h_{1}^{t} ,h_{2}^{t} , \ldots ,h_{{L_{h} }}^{t} } \right\}\), et le décodeur décode l’état caché \(H^{t}\) pour générer la sortie \(Y^{t} = \left\{ {y_{1}^{t} ,y_{2}^{t} , \ldots ,y_{{L_{y} }}^{t} } \right\}\). Pendant ce processus itératif de décodage dynamique, le décodeur calcule un nouvel état caché \(h_{k + 1}^{t}\) en fonction de l’état précédent \(h_{k}^{t}\), ainsi que d’autres sorties nécessaires à l’étape k. Ensuite, on obtient la valeur prédite \(y_{k + 1}^{t}\) pour la séquence \(\left( {k + 1} \right){\text{ème}}\).
L’architecture encodeur-décodeur présente une méthode pour traiter les données de séquences longues, la rendant applicable à la prévision à long terme des séries temporelles. La structure du modèle Transformer traditionnel est illustrée dans la Fig. 1. À gauche de la Fig. 1, l’encodeur est composé de N couches identiques. Chaque couche comprend deux sous-couches : une couche d’auto-attention multi-têtes et un réseau neuronal entièrement connecté. Des connexions résiduelles et une normalisation sont utilisées entre chaque sous-couche pour améliorer les performances. Le décodeur à droite de la Fig. 1 est similaire à l’encodeur, avec une couche d’auto-attention multi-têtes supplémentaire par rapport à l’encodeur.
Intégration et codage positionnels
L’intégration est une technique de prétraitement de données fréquemment utilisée dans les prédictions de réseaux neuronaux pour les tâches de traitement automatique du langage naturel. Elle facilite la fourniture d’informations de caractéristiques plus détaillées à partir des données originales en étendant leurs dimensions. Dans ce modèle, les entrées de l’encodeur, qui sont les données historiques de prix des 20 derniers jours désignées par X = \(\left\{ {x_{t} :1, \ldots 20} \right\} \in R^{20}\), subissent une couche d’incorporation linéaire des mêmes 512 dimensions que le Transformer standard. Cette transformation produit des données caractéristiques multidimensionnelles de dimension \(R^{20 \times 512}\), facilitant les processus ultérieurs.
Mécanisme d’auto-attention
Le mécanisme d’attention se concentre sur des régions locales cruciales pour économiser les ressources de calcul et acquérir rapidement les informations les plus précieuses. Le mécanisme d’auto-attention du Transformer standard est défini comme suit :
$$ Attention\left( {Q,K,V} \right) = softmax\left( {\frac{{{\text{QK}}^{{\text{T}}} }}{\sqrt d }} \right){\text{V}} $$
où Q, K et V sont respectivement les matrices de requête, de clé et de valeur. Dans cet exemple, l’entrée de l’encodeur composée de données historiques des 20 derniers jours subit une intégration et un codage de position avant de subir des calculs de mécanisme d’auto-attention, ce qui donne lieu à une reconstruction des données. L’entrée, composée initialement de données mutuellement indépendantes sur les 20 jours, est reconstruite en fonction des poids d’attention qui capturent les relations ou corrélations inter-jours. La sortie pour chaque jour peut être considérée comme une agrégation des données des 20 jours, pondérée et agrégée selon les scores d’attention obtenus à partir de la fonction softmax. En essence, l’attention multi-têtes peut être comprise comme de multiples mécanismes d’auto-attention fonctionnant en parallèle.
Source : www.nature.com